注意:在SQL SERVER中使用NChar、NVarchar和NText_Mssql数据库教程
推荐:SQL参数化查询的另一个理由――命中执行计划1概述 SQL语言的本质就是一串伪代码,表达的是做什么,而不是怎么做的意思。如其它语言一样,SQL语句需要编译之后才能运行,所以每一条SQL是需要通过编译器解释才能运行的(在这之间还要做SQL的优化)。而这些步骤都是需要运行成本,所以在数据库中有一个叫做执行计划的
前天同事在帮客户录数据的时候,发现有一个人的名字里有个“㛃”(念jie,同“洁”)字,但用搜狗拼音和万能五笔都打不出来,我百度了一下,找到了一篇搜狗论坛的建议帖,有人建议搜狗拼音里增加“
”字的输入,下面跟帖的人贴出了这个“㛃”字。
既然字已经找到,我以为一切OK了,把它复制到飞秋里发给同事,竟然显示的是“?”!这是一个神马情况啊?
我立马又去翻那个帖子,在下面看到了论坛版主的回复:
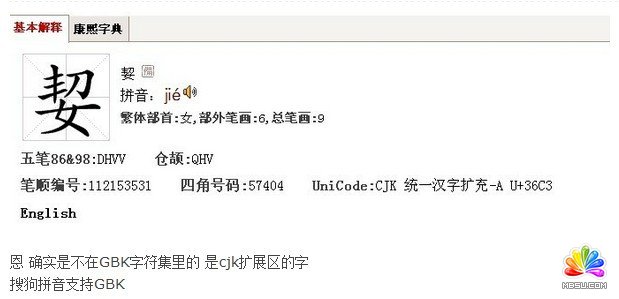
貌似是编码的问题啊,我又把它复制到一个新建的记事本里,保存的时候果然出现了提示:
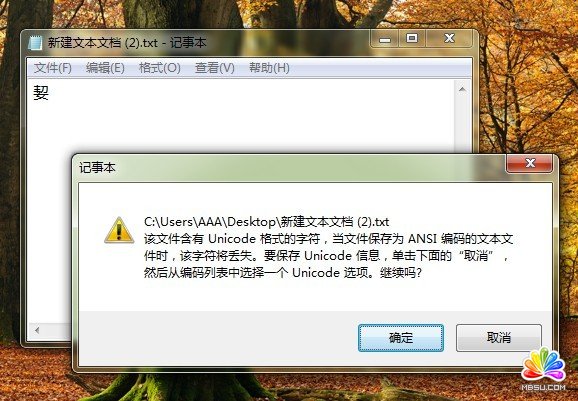
果然是编码的问题啊!这时候,我突然想到,存放姓名的字段用的是varchar型,它能不能存这个字呢?一试,果然也是一个问号!改用nvarchar型字段来存,果断是没问题的。查了下SQL SERVER联机丛书,看到varchar同nvarchar的区别:
除下列情况之外,nchar、nvarchar 和 ntext 的使用分别与 char、varchar 和 text 的使用相同:
Unicode 支持更大范围的字符。
存储 Unicode 字符需要更大的空间。
nchar 列的最大大小为 4,000 个字符,与 char 和 varchar 不同,它们为 8,000 个字符。
使用最大说明符,nvarchar 列的最大大小为 2^31-1 字节。有关 nvarchar(max) 的详细信息,请参阅使用大值数据类型。
Unicode 常量以 N 开头指定:N'A Unicode string'。
所有 Unicode 数据使用由 Unicode 标准定义的字符集。用于 Unicode 列的 Unicode 排序规则以下列属性为基础:区分大小写、区分重音、区分假名、区分全半角和二进制。
SQL SERVER里建表,我一直用的都是varchar,总感觉nvarchar除了存储中文的时候在长度和字符数上有统一性的好处之外,基本没有什么需要用到的地方。这回得了教训,以后再有录入人名或是其他可能出现GBK不包含的生僻字的字段,最好还是使用nchar、nvarchar或ntext,以免在后面给程序留坑。
来源:http://www.cnblogs.com/aaa6032/archive/2012/08/12/2632063.html
分享:一列保存多个ID(将多个用逗号隔开的ID转换成用逗号隔开的名称)背景:在做项目时,经常会遇到这样的表结构在主表的中有一列保存的是用逗号隔开ID。如,当一个员工从属多个部门时、当一个项目从属多个城市时、当一个设备从属多个项目时,很多人都会在员工表中加入一个deptIds VARCHAR(1000)列(本文以员工从属多个部门为例),用以保
- sql 语句练习与答案
- 深入C++ string.find()函数的用法总结
- SQL Server中删除重复数据的几个方法
- sql删除重复数据的详细方法
- SQL SERVER 2000安装教程图文详解
- 使用sql server management studio 2008 无法查看数据库,提示 无法为该请求检索数据 错误916解决方法
- SQLServer日志清空语句(sql2000,sql2005,sql2008)
- Sql Server 2008完全卸载方法(其他版本类似)
- sql server 2008 不允许保存更改,您所做的更改要求删除并重新创建以下表
- SQL Server 2008 清空删除日志文件(瞬间日志变几M)
- Win7系统安装MySQL5.5.21图解教程
- 将DataTable作为存储过程参数的用法实例详解
- 相关链接:
- 教程说明:
Mssql数据库教程-注意:在SQL SERVER中使用NChar、NVarchar和NText
 。
。