hashКЭsolrдкКЃСПЪ§ОнЗжВМЪНЫбЫїв§ЧцжаЕФгІгУНЬГЬ_MySQLНЬГЬ
ЭЦМіЃК23ЕРАВШЋУХМгж§MySQLЪ§ОнПтЪЙгУMySQLЃЌАВШЋЮЪЬтВЛФмВЛзЂвтЁЃвдЯТЪЧMySQLЬсЪОЕФ23ИізЂвтЪТЯюЃК 1.ШчЙћПЭЛЇЖЫКЭЗўЮёЦїЖЫЕФСЌНгашвЊПчдНВЂЭЈЙ§ВЛПЩаХШЮЕФЭјТчЃЌФЧУДОЭашвЊЪЙгУSSHЫэЕРРДМгУмИУСЌНгЕФЭЈаХЁЃ 2.гУset passwordгяОфРДаоИФгУЛЇЕФУмТыЃЌШ§ИіВНжшЃЌЯШmysql -u rootЕЧТНЪ§ОнПтЯЕЭГЃЌШЛКѓmys
ЁЁЁЁSolrЪЧвЛИіЖРСЂЕФЦѓвЕМЖЫбЫїгІгУЗўЮёЦїЃЌЫќЖдЭтЬсЙЉРрЫЦгкWeb-serviceЕФAPIНгПкЁЃгУЛЇПЩвдЭЈЙ§httpЧыЧѓЃЌЯђЫбЫїв§ЧцЗўЮёЦїЬсНЛвЛЖЈИёЪНЕФXMLЮФМўЃЌЩњГЩЫїв§.
ЁЁЁЁЛЅСЊЭјДДвЕжаДѓВПЗжШЫЖМЪЧВнИљДДвЕЃЌетИіЪБКђУЛгаЧПОЂЕФЗўЮёЦїЃЌвВУЛгаЧЎШЅТђКмАКЙѓЕФКЃСПЪ§ОнПтЁЃдкетбљбЯОўЕФЬѕМўЯТЃЌвЛХњгжвЛХњЕФДДвЕепДгДДвЕжаЛёЕУГЩЙІЃЌетИіКЭЕБЧАЕФПЊдДММЪѕЁЂКЃСПЪ§ОнМмЙЙгазХБиВЛПЩЗжЕФЙиЯЕЁЃБШШчЮвУЧЪЙгУmysqlЁЂnginxЕШПЊдДШэМўЃЌЭЈЙ§МмЙЙКЭЕЭГЩБОЗўЮёЦївВПЩвдДюНЈЧЇЭђМЖгУЛЇЗУЮЪСПЕФЯЕЭГЁЃаТРЫЮЂВЉЁЂЬдБІЭјЁЂЬкбЖЕШДѓаЭЛЅСЊЭјЙЋЫОЖМЪЙгУСЫКмЖрПЊдДУтЗбЯЕЭГДюНЈСЫЫћУЧЕФЦНЬЈЁЃЫљвдЃЌгУЪВУДУЛЙиЯЕЃЌжЛвЊФмЙЛдкКЯРэЕФЧщПіЯТВЩгУКЯРэЕФНтОіЗНАИЁЃ
ЁЁЁЁФЧдѕУДДюНЈвЛИіКУЕФЯЕЭГМмЙЙФи?етИіЛАЬтЬЋДѓЃЌетРяжївЊЫЕвЛЯТЪ§ОнЗжСїЕФЗНЪНЁЃБШШчЮвУЧЕФЪ§ОнПтЗўЮёЦїжЛФмДцДЂ200ИіЪ§ОнЃЌЭЛШЛвЊИувЛИіЛюЖЏдЄЙРДяЕН600ИіЪ§ОнЁЃ
ЁЁЁЁПЩвдВЩгУСНжжЗНЪНЃККсЯђРЉеЙЛђепзнЯђРЉеЙЁЃ
ЁЁЁЁзнЯђРЉеЙЪЧЩ§МЖЗўЮёЦїЕФгВМўзЪдДЁЃЕЋЪЧЫцзХЛњЦїЕФадФмХфжУдНИпЃЌМлИёдНИпЃЌетИіДњМлЖдгквЛАуЕФаЁЙЋЫОЪЧГаЕЃВЛЦ№ЕФЁЃ
ЁЁЁЁКсЯђРЉеЙЪЧВЩгУЖрИіСЎМлЕФЛњЦїЬсЙЉЗўЮёЁЃетбљвЛИіЛњЦїжЛФмДІРэ200ИіЪ§ОнЁЂ3ИіЛњЦїОЭПЩвдДІРэ600ИіЪ§ОнСЫЃЌШчЙћвдКѓвЕЮёСПдіМгЛЙПЩвдПьЫйХфжУдіМгЁЃдкДѓЖрЪ§ЧщПіЖМбЁдёКсЯђРЉеЙЕФЗНЪНЁЃШчЯТЭМЃК

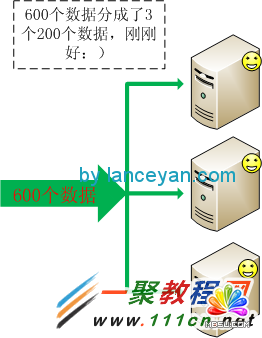
ЁЁЁЁЯждкгаИіЮЪЬтСЫЃЌет600ИіЪ§ОнШчКЮТЗгЩЕНЖдгІЕФЛњЦїЁЃашвЊПМТЧШчЙћОљКтЗжХфЃЌМйЩшЮвУЧ600ИіЪ§ОнЖМЪЧЭГвЛЕФзддіidЪ§ОнЃЌДг1~600ЃЌЗжГЩ3 ЖбПЩвдВЩгУ id mod 3ЕФЗНЪНЁЃЦфЪЕдкецЪЕЛЗОГПЩФмВЛЪЧетжжidЪЧзжЗћДЎЁЃашвЊАбзжЗћДЎзЊБфЮЊhashcodeдйНјааШЁФЃЁЃ
ЁЁЁЁФПЧАПДЦ№РДЪЧВЛЪЧНтОіЮвУЧЕФЮЪЬтСЫЃЌЫљгаЪ§ОнЖМКмКУЕФЗжЗЂВЂЧвУЛгаДяЕНЯЕЭГЕФИКдиЁЃЕЋШчЙћЮвУЧЕФЪ§ОнашвЊДцДЂЁЂашвЊЖСШЁОЭУЛгаетУДШнвзСЫЁЃвЕЮёдіЖрдѕУДАьЃЌДѓМвАДееЩЯУцЕФКсЯђРЉеЙжЊЕРашвЊдіМгвЛЬЈЗўЮёЦїЁЃЕЋЪЧОЭЪЧвђЮЊдіМгетвЛЬЈЗўЮёЦїДјРДСЫвЛаЉЮЪЬтЁЃПДЯТУцетИіР§згЃЌвЛЙВ9ИіЪ§ЃЌашвЊЗХЕН2ЬЈЛњЦї(1ЁЂ2)ЩЯЁЃИїИіЛњЦїДцЗХЮЊЃК1КХЛњЦїДцЗХ1ЁЂ3ЁЂ5ЁЂ7ЁЂ9 ЃЌ2КХЛњЦїДцЗХ 2ЁЂ4ЁЂ6ЁЂ8ЁЃШчЙћРЉеЙвЛЬЈЛњЦї3ШчКЮЃЌЪ§ОнОЭвЊЗЂЩњДѓЧЈвЦЃЌ1КХЛњЦїДцЗХ1ЁЂ4ЁЂ7, 2КХЛњЦїДцЗХ2ЁЂ5ЁЂ8, 3КХЛњЦїДцЗХ3ЁЂ6ЁЂ9ЁЃШчЭМЃК
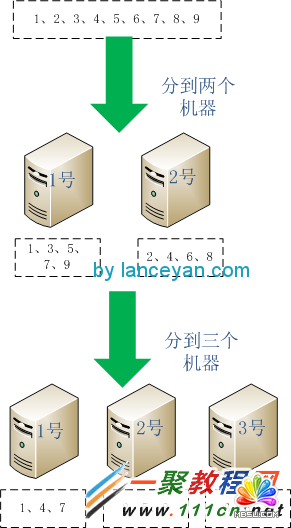
ЁЁЁЁДгЭМжаПЩвдПДГі 1КХЛњЦїЕФ3ЁЂ5ЁЂ9ЧЈвЦГіШЅСЫЁЂ2КУЛњЦїЕФ4ЁЂ6ЧЈвЦГіШЅСЫЃЌАДееаТЕФжШађдйжиаТЗжХфСЫвЛБщЁЃЪ§ОнСПаЁЕФЛАжиаТЗжХфвЛБщДњМлВЂВЛДѓЃЌЕЋШчЙћЮвУЧгЕгаЩЯвкЁЂЩЯTМЖЕФЪ§ОнетИіВйзїГЩБОЪЧЯрЕБЕФИпЃЌЩйдђМИИіаЁЪБЖрдђЪ§ЬьЁЃВЂЧвЧЈвЦЕФЪБКђдЪ§ОнПтЛњЦїИКдиБШНЯИпЃЌФЧДѓМвОЭгавЩЮЪСЫЃЌЪЧВЛЪЧетжжЫЎЦНРЉеЙЕФМмЙЙЗНЪНВЛЬЋКЯРэ?
ЁЁЁЁ—————————–ЛЊРіЗжИюЯп—————————————
ЁЁЁЁвЛжТадhashОЭЪЧдкетжжгІгУБГОАЬсГіРДЕФЃЌЯждкБЛЙуЗКгІгУгкЗжВМЪНЛКДцЃЌБШШчmemcachedЁЃЯТУцМђЕЅНщЩмЯТвЛжТадhashЕФЛљБОдРэЁЃзюдчЕФАцБО http://dl.acm.org/citation.cfm?id=258660ЁЃЙњФкЭјЩЯгаКмЖрЮФеТЖМаДЕФБШНЯКУЁЃШчЃК http://blog.csdn.net/x15594/article/details/6270242
ЁЁЁЁЯТУцМђЕЅОйИіР§згРДЫЕУївЛжТадhashЁЃ
ЁЁЁЁзМБИЃК1ЁЂ2ЁЂ3 Ш§ЬЈЛњЦї
ЁЁЁЁЛЙгаД§ЗжХфЕФ9ИіЪ§ 1ЁЂ2ЁЂ3ЁЂ4ЁЂ5ЁЂ6ЁЂ7ЁЂ8ЁЂ9
ЁЁЁЁвЛжТадhashЫуЗЈМмЙЙ
ЁЁЁЁВНжш
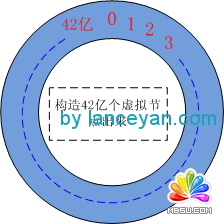
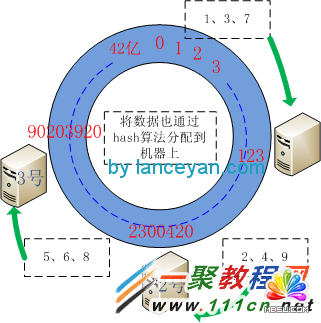
ЁЁЁЁвЛЁЂЙЙдьГіРД 2ЕФ32ДЮЗН ИіащФтНкЕуГіРДЃЌвђЮЊМЦЫуЛњРяУцЪЧ01ЕФЪРНчЃЌНјааЛЎЗжЪБВЩгУ2ЕФДЮЗНЪ§ОнШнвзЗжХфОљКтЁЃСэ 2ЕФ32ДЮЗНЪЧ42вкЃЌЮвУЧОЭЫугаГЌДѓСПЕФЗўЮёЦївВВЛПЩФмГЌЙ§42вкЬЈАЩЃЌРЉеЙКЭОљКтадЖМБЃжЄСЫЁЃ
ЁЁЁЁЖўЁЂНЋШ§ЬЈЛњЦїЗжБ№ШЁIPНјааhashcodeМЦЫу(етРявВПЩвдШЁhostnameЃЌжЛвЊФмЙЛЮЈвЛЧјБ№ИїИіЛњЦїОЭПЩвдСЫ)ЃЌШЛКѓгГЩфЕН2ЕФ32ДЮЗНЩЯШЅЁЃБШШч1КХЛњЦїЫуГіРДЕФhashcodeВЂЧвmod (2^32)ЮЊ 123(етИіЪЧащЙЙЕФ)ЃЌ2КХЛњЦїЫуГіРДЕФжЕЮЊ 2300420ЃЌ3КХЛњЦїЫуГіРДЮЊ 90203920ЁЃетбљШ§ЬЈЛњЦїОЭгГЩфЕНСЫетИіащФтЕФ42вкЛЗаЮНсЙЙЕФНкЕуЩЯСЫЁЃ
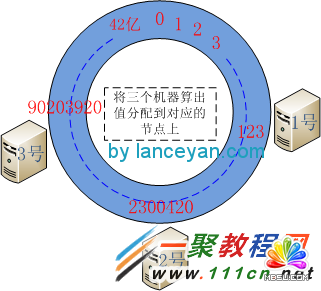
ЁЁЁЁШ§ЁЂНЋЪ§Он(1-9)вВгУЭЌбљЕФЗНЗЈЫуГіhashcodeВЂЖд42вкШЁФЃНЋЦфХфжУЕНЛЗаЮНкЕуЩЯЁЃМйЩшетМИИіНкЕуЫуГіРДЕФжЕЮЊ 1ЃК10ЃЌ2ЃК23564ЃЌ3ЃК57ЃЌ4ЃК6984ЃЌ5ЃК5689632ЃЌ6ЃК86546845ЃЌ7ЃК122ЃЌ8ЃК3300689ЃЌ9ЃК135468ЁЃПЩвдПДГі 1ЁЂ3ЁЂ7аЁгк123ЃЌ 2ЁЂ4ЁЂ9 аЁгк 2300420 Дѓгк 123ЃЌ 5ЁЂ6ЁЂ8 Дѓгк 2300420 аЁгк90203920ЁЃДгЪ§ОнгГЩфЕНЕФЮЛжУПЊЪМЫГЪБеыВщевЃЌНЋЪ§ОнБЃДцЕНевЕНЕФЕквЛИіCacheНкЕуЩЯЁЃШчЙћГЌЙ§2^32ШдШЛевВЛЕНCacheНкЕуЃЌОЭЛсБЃДцЕНЕквЛИіCacheНкЕуЩЯЁЃвВОЭЪЧ1ЁЂ3ЁЂ7НЋЗжХфЕН1КХЛњЦїЃЌ2ЁЂ4ЁЂ9НЋЗжХфЕН2КХЛњЦїЃЌ5ЁЂ6ЁЂ8НЋЗжХфЕН3КХЛњЦїЁЃ
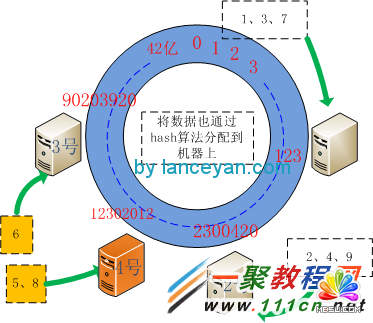
ЁЁЁЁетИіЪБКђДѓМвПЩФмЛсЮЪЃЌЮвЕНЯждкУЛгаПДМћвЛжТадhashДјРДШЮКЮКУДІЃЌБШДЋЭГЕФШЁФЃЛЙдіМгСЫИДдгЖШЁЃЯждкТэЩЯРДзівЛаЉЙиМќадЕФДІРэЃЌБШШчЮвУЧдіМгвЛЬЈЛњЦїЁЃАДеедРДЮвУЧашвЊАбЫљгаЕФЪ§ОнжиаТЗжХфЕНЫФЬЈЛњЦїЁЃвЛжТадhashдѕУДзіФи?Яждк4КХЛњЦїМгНјРДЃЌЫћЕФhashжЕЫуГіРДШЁФЃКѓЪЧ12302012ЁЃ 5ЁЂ8 Дѓгк2300420 аЁгк12302012 ЃЌ6 Дѓгк 12302012 аЁгк90203920 ЁЃетбљЕїећЕФжЛЪЧАб5ЁЂ8Дг3КХЛњЦїЩОГ§ЃЌ4КХЛњЦїжаМгШы 5ЁЂ8ЁЃ
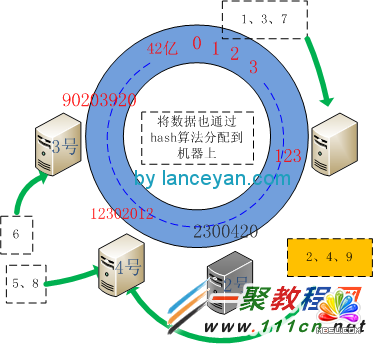
ЁЁЁЁЭЌРэЃЌЩОГ§ЛњЦїдѕУДзіФиЃЌМйЩш2КХЛњЦїЙвЕєЃЌЪмгАЯьЕФвВжЛЪЧ2КХЛњЦїЩЯЕФЪ§ОнБЛЧЈвЦЕНРыЫќНкЕуЃЌЩЯЭМЮЊ4КХЛњЦїЁЃ
ЗжЯэЃКMySQL 5.0 Ъ§ОнПтаТЬиадЕФДцДЂЙ§ГЬЕБФуЬсНЛвЛИіВщбЏЕФЪБКђЃЌMySQLЛсЗжЮіЫќЃЌПДЪЧЗёПЩвдзівЛаЉгХЛЏЪЙДІРэИУВщбЏЕФЫйЖШИќПьЁЃетвЛВПЗжНЋНщЩмВщбЏгХЛЏЦїЪЧШчКЮЙЄзїЕФЁЃШчЙћФуЯыжЊЕРMySQLВЩгУЕФгХЛЏЪжЖЮЃЌПЩвдВщПДMySQLВЮПМЪжВсЁЃ ЕБШЛЃЌMySQLВщбЏгХЛЏЦївВРћгУСЫЫїв§ЃЌЕЋЪЧЫќвВЪЙгУСЫЦфЫќвЛаЉаХЯЂЁЃР§ШчЃЌШч
- 23ЕРАВШЋУХМгж§MySQLЪ§ОнПт
- MySQL 5.0 Ъ§ОнПтаТЬиадЕФДцДЂЙ§ГЬ
- MySqlЙмРэЕФвЛЕуаФЕУ
- mysqlЕМШыЪ§ОнПтЮФМўзюДѓЯожЦЕФаоИФЗНЗЈ
- MysqlДцДЂв§ЧцInnoDBКЭMyisamЕФСљДѓЧјБ№
- MysqlдЫааЛЗОГгХЛЏ(LinuxЯЕЭГ)
- MySQLВщбЏЕФадФмгХЛЏЛљДЁНЬГЬ
- MySQL дкwindowsЩЯЕФАВзАЯъЯИНщЩм
- sql server 2005ЪБЗЂЩњ18452ДэЮѓНтОіЗНЗЈ
- MySQLзжЖЮЕФШЁжЕЗЖЮЇ
- mysql_unbuffered_queryгыmysql_queryЕФЧјБ№
- mysql ИДжЦБэЪ§ОнЃЌБэНсЙЙЕФ3жжЗНЗЈ
MySQLНЬГЬRssЖЉдФБрГЬНЬГЬЫбЫї
MySQLНЬГЬЭЦМі
- MySQLГЃгУУќСюаазмНсЪеМЏ
- ЩюШыРэНтSQLЕФЫФжжСЌНг-зѓЭтСЌНгЁЂгвЭтСЌНгЁЂФкСЌНгЁЂШЋСЌНг
- mysqlУмТыЙ§ЦкЕМжТСЌНгВЛЩЯmysql
- MySQLБЪМЧжЎЪгЭМЕФЪЙгУЯъНт
- MySQLзжЖЮЕФШЁжЕЗЖЮЇ
- MySQLЕФАВШЋЮЪЬтДгАВзАПЊЪМЫЕЦ№
- НтЮіmysqlжа:ЕЅБэdistinctЁЂЖрБэgroup byВщбЏШЅГ§жиИДМЧТМ
- MYSQLЕФЕМШыЕМГігыЛЙдБИЗн
- Win7 ЯЕЭГЩЯАВзАSQL Server 2008ЭМНтНЬГЬ
- ЭјеОЪ§ОнЖрСЫЗжвГТ§ИУдѕУДАьЃП
ВТФувВЯВЛЖПДетаЉ
- Ш§ИіSQLЪгЭМВщГіЫљгаSQL ServerЪ§ОнПтзжЕф
- НтОіSQL ServerЪ§ОнПтШЈЯоГхЭЛЕФШ§ДѓУюеа
- SQL ServerЪ§ОнПтдіЧПАцБИЗнЬхбщ
- бађНЅНјНВНтЪ§ОнБэЕФЪЎЖўИіЩшМЦддђ
- ЬИSQL Data ServicesНЋГЩЮЊдЦжаЭъећЕФЪ§ОнПт
- ЮЊКЮАбФуЕФЪ§ОнПтжУгкАцБОПижЦжЎЯТ
- charЁЂvarcharЁЂtextКЭncharЁЂnvarcharЁЂntextЕФЧјБ№
- mssql2005Ъ§ОнПтОЕЯёДюНЈНЬГЬ
- гУвЛЬѕsqlШЁЕУЕк10ЕНЕк20ЬѕЕФМЧТМ
- НтЖСSQL ServerЪ§ОнПтБИЗнЕФЗНЗЈ
- ЯрЙиСДНгЃК
ИДжЦБОвГСДНг| ЫбЫїhashКЭsolrдкКЃСПЪ§ОнЗжВМЪНЫбЫїв§ЧцжаЕФгІгУНЬГЬ
- НЬГЬЫЕУїЃК
MySQLНЬГЬ-hashКЭsolrдкКЃСПЪ§ОнЗжВМЪНЫбЫїв§ЧцжаЕФгІгУНЬГЬ
 ЁЃ
ЁЃ